
Why it points directly toward a future where code is disposable, specifications are permanent, and the entire logic of software teams is inverted.
The Problem Spec Driven Development Is Solving
There is a pattern playing out across software teams that have embraced AI coding assistants. In the first days and weeks, the productivity feels extraordinary. You describe what you want, receive working code, tweak it, ship it. Features that used to take a week take an afternoon. The feedback loop collapses. Everything feels faster.
Then month eighteen arrives.
Three developers who built the core of the system have moved on. The AI assistant that helped generate the original code has no memory of why any particular decision was made. The codebase has accumulated layer upon layer of generated code, each layer slightly inconsistent with the ones around it. Nobody is quite sure what the system actually does anymore. They only know what it currently does, and those are increasingly different things.
This is vibe coding debt — and it accumulates faster than traditional technical debt because AI makes it so easy to generate volume without generating clarity. Every AI-generated feature that ships without a specification is a feature whose intent lives nowhere except in the code itself. When the code becomes hard to read, the intent is gone. When the developer who wrote the prompts leaves, context is gone with them.
The deeper problem is not the quality of the code AI generates. It is the quality of the instructions AI receives. Vague prompts produce vague code. Specific, structured, reviewed specifications produce code that can be trusted, verified, and — critically — regenerated.
Spec Driven Development (SDD) is the answer to this problem. It is a methodology that inverts the traditional relationship between intent and implementation. Instead of writing code and hoping the intent can be reconstructed from it later, SDD insists that intent is captured first — completely, unambiguously, and in a form that outlives any individual codebase.
The Mental Model Shift — Four Inversions That Change Everything
Before understanding what SDD is in practice, it is essential to make four mental model shifts. Without these, SDD looks like waterfall planning dressed in modern clothes. With them, it looks like the only rational response to building software in an era when code is cheap to generate and intent is expensive to reconstruct.
Inversion 1 — Specs are the asset. Code is the output.
In traditional software development, code is the primary artifact. Specifications, if they exist at all, are written to guide developers and then discarded or ignored as the codebase evolves. The code is the thing you maintain, protect, and invest in.
SDD inverts this completely. The specification is the asset. The code is the output — no more permanent than a compiled binary. If your specifications are complete and correct, the code can be deleted and regenerated at any time. If your specifications are incomplete or missing, the code is the only record of what the system is supposed to do, and that is a fragile and expensive place to store institutional knowledge.
| Today’s Role | SDD-Era Role | Key Skills Required | Who from Today Can Play This Role |
|---|---|---|---|
| Junior Developer Writes boilerplate, implements tickets, fixes bugs | Spec Reviewer / Spec Engineer Reviews AI-generated specs, refines acceptance criteria | ● Ambiguity detection ● Edge case thinking ● Domain knowledge ● Testability judgment | Junior devs with curiosity, communication skills, and business interest Best candidates: those who ask ‘why’ more than ‘how’ |
| Mid-level Developer Delivers features end to end, mentors juniors | Senior Spec Reviewer / Domain Expert Owns spec quality across multiple features, catches cross-feature conflicts | ● Cross-feature consistency ● Constitution compliance ● Acceptance criteria completeness ● Stakeholder communication | Mid-level devs with strong domain knowledge and analytical thinking Best candidates: those who catch bugs in requirements before coding |
| Senior Developer Architects features, sets patterns, reviews PRs | Seasoned Code Judge Evaluates AI-generated code for structure, security, and architectural soundness | ● Reading code with architectural eyes ● Spotting structural anti-patterns ● Security and performance judgment ● Accept / reject / regenerate decisions | Senior devs with deep implementation experience — this role requires years of having written code to judge it well Best candidates: those who instinctively know what will be hard to maintain |
| Business Analyst Gathers requirements, writes user stories, liaises with stakeholders | Spec Seed Author Articulates intent to seed AI spec generation, owns domain correctness of every spec | ● Intent articulation ● Deep domain expertise ● Stakeholder translation ● Gap identification — what AI cannot know | BAs are the most naturally positioned — this is closest to their existing work, now with AI doing the drafting Best candidates: BAs who understand both business and technology deeply |
| Architect Designs systems, sets tech direction, governs standards | Constitution Designer / Pace Layer Strategist Defines what never changes, what regenerates, and how fast | ● Constitution authorship ● Pace layer thinking ● Cross-system governance ● Regeneration strategy | Senior architects and principal engineers — requires the broadest system view on the team Best candidates: architects who think in decades, not sprints |
| QA Tester Tests code after it is written, writes regression scripts, files bug reports | Quality Architect Authors test specs from acceptance criteria, validates spec quality, validates regeneration | ● Spec QA — catching ambiguity before code generation ● Test spec authorship ● Regeneration validation ● Exploratory testing | QA professionals are the second most naturally positioned — they already think in scenarios, conditions, and expected outcomes Best candidates: QA engineers who write bug reports that developers immediately understand |
Inversion 2 — Tests derive from specs, not from code.
Traditional testing writes tests after writing code. Those tests are coupled to the implementation — they verify that the code does what the code does. When you regenerate the code, those tests may fail not because the behavior changed but because the structure changed. They are testing HOW, not WHAT.
In SDD, tests are derived from the specification before any code exists. They define correct behavior — given this input, when this action occurs, then this output is produced. They are stack-independent. They survive code regeneration. They are not part of the code layer. They are part of the specification layer, and they live in version control alongside the specs, permanently.
This distinction is not just philosophical. It is the practical mechanism that makes regenerability reliable. Tests derived from specs define what correct looks like independently of any implementation. When code is regenerated, the tests tell you definitively whether the regeneration succeeded. Without spec-derived tests, regenerability is a claim. With them, it is a proof.
Inversion 3 — Git stores the spec library, not just the codebase
In traditional development, the git repository is a record of code changes. Commit history tells you what changed in the code. It rarely tells you why, and it almost never tells you what the system was supposed to do at the behavioral level.
In SDD, the git repository is first and foremost a specification library. Every acceptance criterion, every edge case, every business rule, every architectural decision lives in version-controlled specification files alongside the code. The full history of every product decision is preserved, readable by developers and AI agents alike, across every team change and every technology migration.
This means the git repository outlives any individual codebase. When the technology stack changes, the specs survive. When the team changes, the specs survive. When the AI model is upgraded, the specs are still there to generate better code from. The spec library is the intellectual property of the team. The code is just its current expression.
Inversion 4 — AI drafts the spec. Humans own the spec.
A common misconception about SDD is that it requires humans to sit down and write specifications from scratch — that it is a discipline of authorship. It is not. Nobody writes a complete, well-structured spec from a blank page, just as nobody writes boilerplate code from scratch anymore. The reality of SDD in practice is that AI drafts the specification and humans review, refine, and own it.
The actual workflow is: a product manager or developer describes their intent in a few sentences. The AI generates a structured spec — with acceptance criteria, edge cases, and behavioral definitions — from that seed. The human reviews it, catches what the AI missed, adds what the AI could not know, and approves it. The human’s job is judgment and ownership, not authorship from a blank page.
This distinction matters enormously for adoption. “You need to learn to write specs” sounds like more work and will be resisted. “AI drafts the spec, you refine and own it” sounds like what developers and product managers already do when reviewing pull requests — and will be embraced. The critical skill SDD develops is not spec writing. It is spec reviewing — knowing what a good spec looks like, catching what the AI missed, identifying the edge case nobody asked about, recognizing when an acceptance criterion is ambiguous enough to produce two different implementations.
The Central Hypothesis of Spec Driven Development
The hypothesis at the core of SDD can be stated precisely:
If specifications are complete and correct, and tests are derived from those specifications, then code is regenerable at any time from any AI coding agent, and regeneration is verifiable without human judgment.
Therefore: the specification library compounds in value over time. The codebase does not.
This hypothesis has profound implications. If it holds, changing a specification is cheaper than changing code — because you update the spec and regenerate. Migrating to a new technology stack requires no rewriting of business logic — you regenerate from the same specs against a new constitution. Upgrading to a more capable AI model immediately benefits every existing feature — you regenerate and your test suite confirms the improvements.
Every year a team invests in reviewing and refining AI-generated specifications, their spec library becomes more valuable. Every year a team vibe-codes without owning specifications, their codebase becomes harder to understand, more expensive to change, and more dependent on the specific individuals who built it. The compounding goes in opposite directions.
This is where Spec Driven Development connects to a broader architectural principle. In late 2025, software engineer and venture capitalist Chad Fowler extended his concept of immutable infrastructure to code itself, in what he calls the Phoenix Architecture. His central claim: the most durable systems of the AI era will be built from code that is meant to die. Systems designed to burn and be reborn — identical in behavior — without losing their identity.
SDD is the discipline that makes Phoenix Architecture achievable in practice. The specification is the identity that survives the fire. The test suite is the proof that the phoenix rose correctly. The code is what burns. This is not a theoretical future — it is the logical destination of rigorous SDD practiced today.
What a Complete Spec System Looks Like
A mature SDD practice produces specifications across five interconnected layers. Each layer has a distinct audience, a distinct purpose, and a distinct lifetime. Understanding what belongs in each layer — and critically what does NOT belong — is one of the most important disciplines in SDD.
The Constitution
The constitution is the foundational document that governs every specification and every code generation in the project. It captures non-negotiable principles: technology stack choices, architectural patterns, security requirements, accessibility standards, testing philosophy, and organizational conventions. It is the highest-level spec — the one that never burns, because it defines the architectural identity of the system.
GitHub's open-source Spec-Kit formalizes the constitution as the first artifact created in any new project. Every subsequent specification generation checks its output against the constitution. If a spec violates a constitutional principle, it is flagged before any code is written.
The Feature Specification
The feature spec describes what a feature does in purely behavioral terms. It is written in plain language. It contains no code. It is readable by non-developers. It is owned collaboratively by product managers, business analysts, developers, and testers. It captures user stories, acceptance criteria, and edge cases. The critical discipline: the spec describes what correct behavior looks like, entirely independently of how that behavior will be implemented.
The Implementation Plan
The plan translates the feature specification into a technical roadmap — components needed, how they interact, data flows, and implementation sequence. A well-written plan contains no implementation code. It describes structure and behavior in language that a technical reviewer can evaluate without running anything. This is a discipline that takes practice: AI tools naturally want to include code in plans, and teams must explicitly instruct them not to.
API and Data Contracts
Contracts define the shapes of data moving through the system — inputs, outputs, error types, and interface definitions. They are described as types and schemas, not as implementation code. They form the binding interface between components. Unlike code, contracts survive the regeneration of any individual component that implements them.
The Test Specification
The test spec is the most critical and most underappreciated layer of the specification system. It defines what passing looks like — independently of any implementation. Every acceptance criterion in the feature spec maps to one or more test cases in the test spec. Tests are behavioral: given this input, when this action occurs, then this output is produced. They do not test code structure. They test behavioral correctness. They are the bridge between imperfect specifications and reliable regeneration.
The Tools Available Today
| Tool | Approach and Best Fit |
|---|---|
| GitHub Spec-Kit (open source) | Full workflow: constitution → specify → plan → tasks → implement. Works with Claude Code, Copilot, Gemini. Best for: developer-led teams, any tech stack |
| Amazon Kiro | IDE-native SDD using EARS requirements syntax. Deep AWS integration. Best for: AWS-native teams wanting structured guidance |
| Tessl (private beta) | Spec-as-primary-artifact — humans only edit specs, never code. Most radical Phoenix interpretation. Best for: teams ready for full SDD commitment |
| Claude Code + spec files | No dedicated SDD tooling. Specs are plain markdown files you write and structure yourself, committed to the repo. Claude Code reads them as context each session — there is no special SDD file format. Best for: teams wanting immediate adoption with no new tooling, accepting that spec structure and discipline must be maintained manually |
The Main Drawbacks of SDD Today
SDD is a compelling methodology. It is also an emerging one, and intellectual honesty requires acknowledging its real limitations. Teams that adopt SDD naively — without understanding these drawbacks — will be disappointed. Teams that understand them and design around them will succeed.
The Spec Completeness Problem
The most fundamental limitation of SDD is that AI-generated specifications — even when refined by humans — contain implicit assumptions and gaps. Every spec, no matter how carefully reviewed, leaves some behavior undefined. The AI that generates the spec makes one set of assumptions. The AI that generates the code may make different ones. Two regenerations from the same spec may produce code that behaves identically in tested scenarios and differently in untested ones — not because the AI is inconsistent, but because the spec was genuinely underspecified.
There is no perfect solution to this problem. The practical mitigation is to treat every gap the AI fills with an assumption as a signal that the spec needs improvement. When generated code makes a choice the spec did not explicitly address, the answer is to update the spec — not to patch the code.
The Non-Determinism Problem
Large language models are fundamentally non-deterministic. The same specification, given to the same AI model twice, will produce functionally similar but structurally different code. Variable names differ. Function organization differs. Error handling approaches differ. The code may pass the same test suite in both cases and yet be internally inconsistent in ways that accumulate over time as the codebase grows.
This is a real limitation with no complete solution today. The constitution mitigates it by constraining structural choices — forcing the AI to follow naming conventions, folder structures, and architectural patterns. But even with a detailed constitution, regeneration produces variation. Section 6 addresses this problem in depth.
The Context Window Problem
Modern AI models have large context windows — 200,000 tokens and growing. A real enterprise codebase is millions of tokens. When regenerating a component in isolation, the AI cannot hold the entire system in context. It may make decisions that are locally correct but globally inconsistent — choosing a data structure that conflicts with another component, or implementing an error handling pattern that differs from the rest of the system.
This limits reliable regeneration to feature-level and module-level components. Full application regeneration remains unreliable for large systems. Context window limits will grow over time, and this problem will diminish — but it is a real constraint today that teams need to design around by keeping components small, well-bounded, and independently regenerable.
The Implicit Knowledge Problem
Over time, every codebase accumulates decisions that were never written into specifications. Performance optimizations discovered through profiling. Security patches applied after a vulnerability. Workarounds for third-party library bugs. Hard-won business logic that emerged from production incidents. These live in the code, not in the specs. Regeneration from specs silently loses all of them.
The discipline this demands is ruthless: every production decision that is not in the spec should be added to the spec before the next regeneration. This is harder than it sounds culturally — it requires developers to treat spec maintenance as part of their daily work, not as a documentation afterthought.
The Adoption Friction Problem
Writing good specifications is harder than writing code for most developers. It requires a different kind of thinking — describing behavior without reaching for implementation, writing acceptance criteria that are specific enough to be testable but not so specific that they prescribe structure. Most developers have not been trained to do this. The learning curve is real, and the temptation to skip straight to generating code is always present.
Teams that succeed with SDD treat spec review as a skill to be developed deliberately, not a bureaucratic process to be endured. AI drafts the spec — the human's job is to catch what the AI missed, add what only a domain expert would know, and own the result. This is a more achievable habit to build than writing specs from scratch, and it maps naturally to the review skills developers already apply to pull requests.
The Over-Engineering Risk
SDD can easily become a new form of waterfall planning if practiced without discipline. Teams that write exhaustive specifications for every conceivable feature before writing any code are not doing SDD — they are doing big upfront design with AI assistance. SDD is intended to be iterative: write the spec for the next feature, generate it, validate it, learn from it, refine the process.
The Tooling Immaturity Problem
The tooling ecosystem for SDD, while growing fast, is still primarily CLI-based and developer-oriented. Non-developers — the product managers, business analysts, and testers who should be primary contributors to specifications — are largely excluded from today's tooling. This limits the organizational reach of SDD and concentrates specification writing in the one role that is most tempted to skip it.
The Non-Determinism Problem in Depth
Of all the drawbacks of SDD, the non-determinism of LLMs deserves the deepest examination, because it is the one that most directly challenges the central hypothesis. If the same spec produces different code every time, in what sense is the code regenerable? In what sense does the spec define the system?
The answer requires separating two distinct concerns: behavioral equivalence and structural consistency.
Behavioral equivalence means two code implementations produce the same outputs for the same inputs, handle the same edge cases, and respect the same constraints. Structural consistency means two implementations are organized, named, and architected in the same way.
AI regeneration from specs reliably produces behavioral equivalence — when tests pass. It does not reliably produce structural consistency — even with a constitution. This distinction matters because structural inconsistency accumulates into long-term maintainability problems. A codebase where every regeneration produces slightly different variable naming conventions, slightly different error handling patterns, and slightly different module organization becomes progressively harder to reason about — even if every individual component is functionally correct.
The practical implication is that non-determinism does not invalidate SDD — it constrains it. The constitution needs to be more detailed than most teams initially write, covering not just technology choices but naming patterns, error handling conventions, logging standards, and code organization principles. The test suite needs to be comprehensive enough that behavioral equivalence is actually proven, not assumed. And teams need to accept that structural variation will occur and manage it through regular architecture reviews rather than expecting perfect consistency from regeneration alone.
The honest summary of non-determinism in SDD:
Same spec, run twice, produces different code — that is expected and acceptable. Same spec, run twice, produces different behavior — that is a spec gap, not an AI problem.
Non-determinism is managed by tests, not eliminated by better prompting.
How Good Test Specifications Solve the Shortcomings
The shortcomings of SDD — spec incompleteness, AI non-determinism, implicit knowledge gaps — share a common root: the absence of an independent, objective definition of what correct behavior means. Tests derived from specifications are that definition. They are the practical mechanism that transforms SDD from a promising methodology into a reliable engineering practice.
Tests absorb non-determinism
When AI generates different code from the same spec on different runs, the test suite provides the objective arbiter. If both implementations pass the full test suite, they are behaviorally equivalent — which is the only equivalence that matters for the system's users. The structural differences are real but manageable. The behavioral equivalence is proven. Non-determinism becomes a variation in structure, not a variation in correctness.
Tests expose spec gaps
Every time an AI fills a gap in a spec with an assumption — choosing a default behavior the spec did not address — that assumption either matches what the test suite expects or it does not. When it does not, the test fails and the spec gap is revealed. This is the feedback loop that drives spec improvement. Without a comprehensive test suite, spec gaps produce code that seems to work until it encounters a real user in a real scenario. With a comprehensive test suite, spec gaps produce failing tests — which is a much cheaper discovery mechanism.
Tests make regeneration verifiable
Regeneration without verification is a claim. Regeneration with a passing test suite is a proof. This is the key distinction between SDD as a philosophy and SDD as an engineering practice. The test suite transforms the abstract promise — "the spec is the source of truth, the code can be regenerated" — into a concrete, binary, automatable answer: regeneration succeeded because all tests passed, or it did not because some failed.
Tests capture implicit knowledge
When production incidents reveal behavior that was never in the spec — edge cases discovered in the wild, performance characteristics under real load, security considerations that emerged from a vulnerability — the discipline is to write tests for them before fixing the code. Those tests encode the implicit knowledge into the specification layer. The next regeneration will respect it because the tests will enforce it. Over time, the test suite becomes the accumulated memory of every production lesson the team has ever learned.
This leads to the most important equation in the entire SDD-Phoenix Architecture relationship:
The key equation:
Good specs define intent. Good tests define correctness independently of code. Non-deterministic AI + deterministic tests = deterministic outcomes.
Code regenerated from specs is reliable — not because AI is deterministic, but because tests catch every deviation from correct behavior.
Phoenix Architecture becomes real today for any feature with both.
The Role of Testers in an SDD World
Of all the role changes that SDD brings, the transformation of the tester's role is the most profound — and the most positive for talented QA professionals.
In traditional development, testers are downstream of developers. Code is written, then testers verify it works. The tester's job is fundamentally reactive — finding problems in something that already exists. In SDD, testers move upstream. Their most important work happens before any code is generated.
Spec QA — catching ambiguity before it becomes a bug
The single most valuable thing a tester can do in an SDD workflow is review specifications before they are handed to an AI coding agent. A tester who asks "what happens when the email field is empty?" before code generation prevents a bug. A tester who notices that two acceptance criteria contradict each other prevents a week of confusion. The earlier in the process a problem is caught, the cheaper it is to fix — and spec review is the earliest possible intervention point.
Acceptance criteria authorship
In SDD, acceptance criteria are not added to tickets as an afterthought. They are the primary artifact that defines what a feature must do. Testers are uniquely positioned to write acceptance criteria — they think naturally in terms of conditions, scenarios, and expected outcomes. In an SDD workflow, the tester's acceptance criteria become the direct source of the test specification, which becomes the arbiter of every code generation.
Regeneration validation — a brand new role
When code is regenerated from specifications — whether due to a spec change, a tech stack migration, or an AI model upgrade — someone needs to verify that the regeneration preserved all behavior, including behavior that was not explicitly tested. This is exploratory testing applied to regenerated code: does the phoenix that rose from the ashes actually behave the same as the one that burned? This role does not exist in traditional development. It is entirely new, and it requires exactly the judgment, curiosity, and system knowledge that the best testers possess.
Exploratory testing becomes more important, not less
A common concern is that AI-generated test suites will automate testers out of existence. The opposite is true for exploratory testing. AI can generate tests from specified behavior. It cannot discover behavior that was never specified. The tester who uses the system like a real user, who finds the edge cases that no one thought to specify, who notices that the system is technically correct but practically unusable — that work becomes more valuable as the formally specified and tested surface area grows. Exploratory testing covers what specification can never anticipate.
In summary: the tester of the future is not a quality checker at the end of the process. They are a quality architect at the beginning of it — defining what correct means before anything is built, and verifying that the system that emerges matches that definition.
The Role of Developers in an SDD World
The developer's role in SDD shifts from primary code author to something more like a system architect, specification reviewer, and quality arbiter. This is not a diminishment — it is an elevation. The work that machines cannot do well becomes the work that defines developer value.
Constitution authors and architectural guardians
The constitution is the most important document in an SDD project, and it requires the deepest technical expertise to write well. Deciding which architectural patterns are non-negotiable, which technology choices should be locked in versus left flexible, which security requirements are absolute — this is senior developer and architect work. The constitution encodes the accumulated architectural judgment of the team. Getting it right determines the quality of every code generation that follows.
Spec reviewers and implementation evaluators
When AI generates a plan or an implementation, the developer's job is to evaluate it as a system architect — does this approach make sense given the broader system? Does the data model created for this feature conflict with an existing one? Does the API design create future maintenance burdens? These judgments require deep system knowledge and experience that AI does not have. The developer who excels at SDD is not the one who can write the most code — it is the one who can most quickly assess whether generated code is architecturally sound.
Spec gap identifiers
When generated code makes a surprising choice — implementing something in an unexpected way, handling an edge case differently than the developer would have — the SDD-fluent developer asks: is this a spec gap or a code error? If the spec does not address this case, the answer is to update the spec. If the spec addresses it but the code is wrong, regenerate. This discipline of identifying spec gaps rather than patching code is one of the most important habits in SDD and one of the hardest to build.
Domain experts and business translators
The best developers in an SDD world are those who deeply understand the business domain — who can sit with a product manager, review an AI-generated specification, and immediately spot the edge case the AI did not surface, the business constraint the prompt did not capture, or the user scenario that makes an acceptance criterion ambiguous. This has always been a valuable skill. In SDD it becomes the central one. The developer who can extract intent from a stakeholder, seed a spec generation with the right context, and then review the result with genuine domain judgment creates more value than the developer who can implement a requirement fastest.
Skills Developers Need to Thrive in the SDD Era
The SDD era does not require developers to learn entirely new disciplines — it requires existing disciplines to be reweighted. Some skills that were peripheral become central. Some skills that were central become peripheral. Understanding this reweighting is essential for developers who want to remain highly valuable as SDD adoption grows.
Skills that grow dramatically in value
| Skill | Why It Matters More in SDD |
|---|---|
| Spec review and refinement | AI drafts specs — humans review and own them. Knowing what a good spec looks like, catching what AI missed, and recognising ambiguous acceptance criteria is the primary developer skill in SDD |
| Systems thinking and cross-feature reasoning | Understanding how one feature's spec interacts with another's before code exists prevents regeneration conflicts |
| Domain expertise and business knowledge | Translating business intent into testable specifications requires deep understanding of what the business actually needs |
| Architecture judgment and constitution design | The constitution governs every code generation — writing it well requires more architectural depth than writing the code it produces |
| Test design and acceptance criteria thinking | Writing behavioral tests that survive code regeneration requires thinking about correctness independently of implementation |
| AI evaluation and output assessment | Assessing whether AI-generated code is architecturally sound requires judgment that transcends functional testing |
| Prompt engineering and spec structuring | Understanding how AI interprets specifications — and structuring them to minimize misinterpretation — is a learnable and valuable skill |
Skills that depreciate in value
| Skill | Why It Matters Less in SDD |
|---|---|
| Syntax mastery in specific languages | AI generates syntactically correct code reliably — memorizing language syntax is no longer a differentiator |
| Boilerplate and scaffolding knowledge | Framework setup, CRUD generation, and standard patterns are fully automatable from specs |
| Framework-specific implementation patterns | AI knows every framework — knowing how to implement a pattern in a specific framework is less valuable than knowing which pattern to specify |
| Manual debugging of generated code | In SDD, when code is wrong, you fix the spec and regenerate — debugging generated code without updating the spec creates debt |
| Individual productivity in typing code | Code generation speed is no longer a bottleneck — specification quality is |
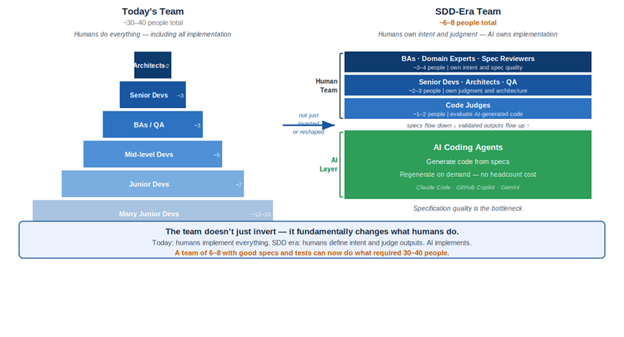
The Team Pyramid Inversion — The Most Disruptive Implication of SDD
Of all the implications of SDD, the most structurally disruptive is what it does to the shape of software engineering teams. Understanding this requires first understanding why today's team pyramid has the shape it does.
Today's pyramid and why it exists
The typical enterprise engineering team today has many junior and mid-level developers, a smaller number of senior developers, and a few architects, business analysts, and principal engineers. This pyramid exists because code was the bottleneck. Implementation was expensive. You needed many hands to translate requirements into working software. Architects and BAs were the planning layer — a small investment in clarity at the top to guide a large workforce of implementation below.
The pyramid reflects the economics of scarce implementation. When implementation is expensive, you need many implementers and relatively few specifiers.
How SDD changes the bottleneck
SDD, combined with AI coding agents, dramatically reduces the cost of implementation. A well-written specification can be translated into working code by an AI agent in minutes. The bottleneck moves. It is no longer implementation. It is specification quality. The constraint on how fast a team can ship valuable, reliable, maintainable software is no longer the number of developers writing code — it is the number of people who can write excellent specifications, design comprehensive test suites, and evaluate generated outputs with architectural judgment.
The team structure that emerges — and why it is not a pyramid at all
As SDD matures, the team does not simply invert its pyramid — it changes shape entirely. The implementation base that justified large numbers of junior developers disappears, because AI becomes the implementation layer. What remains is a small, flat group of senior humans whose job is intent, judgment, and quality. The total team size shrinks dramatically. And critically, the shape is no longer a pyramid at all:
What happens to junior developers
This is the question that most concerns people when they first encounter the team pyramid inversion. If AI handles implementation, what is the entry point into the profession?
The honest answer is that the nature of entry-level work changes significantly. The junior developer who spent their first two years writing CRUD endpoints and debugging API integrations will increasingly be replaced — for that specific work — by AI coding agents.
But the entry-level work that remains, and grows, is specification work, test design, and domain learning.
A junior developer in the SDD era earns their expertise by developing deep domain knowledge and learning to review and refine AI-generated specifications with judgment — catching what the AI missed, understanding what the business actually needs, and owning the spec as truth. This is work that requires human judgment, stakeholder communication, and business understanding. This is, arguably, a better entry point into the profession than writing boilerplate code that an AI could generate. The developers who invest in these skills early will have a much stronger foundation than those who spent those years mastering framework-specific implementation patterns that AI renders less relevant.
The emerging Spec Engineer role
A new job title is beginning to appear in forward-thinking organizations: the Spec Engineer. This is someone with enough technical background to review and refine AI-generated specifications with precision, and enough domain knowledge to catch what the AI could not know — the business edge case, the compliance constraint, the real-world usage pattern that no prompt would surface. Their primary output is approved, owned specifications and test cases, not code. This role sits between traditional business analyst and traditional developer, drawing on the best of both. It is the role that most directly reflects the inverted bottleneck of SDD-era software development.
Predictions — Where SDD Leads Over the Next Five Years
SDD is an emerging practice. Most of its most significant implications are still ahead of us. Based on the trajectory of the methodology, the tooling, and the broader AI coding ecosystem, we offer the following predictions:
2026 — SDD becomes standard at AI-forward companies
By end of 2026, SDD will be the default methodology at companies that have seriously committed to AI-native development practices. The evidence will be visible in job postings: requirements for spec review skills, behavioral test design, and AI output evaluation will appear alongside or replace traditional coding skills requirements.
2027 — Web-based SDD tools replace CLI workflows
The CLI-based tools that dominate today's SDD landscape will give way to web-based collaborative platforms that make specification generation and review accessible to non-developers. Product managers will describe intent in plain language and receive AI-generated specs to review and approve. Testers will refine AI-generated acceptance criteria in structured editors. Business analysts will review AI-generated data models through visual tools. The spec files these tools produce will be identical to those that developers produce via CLI — stored in the same git repositories, consumed by the same AI coding agents. The separation between "developer tool" and "product tool" will begin to collapse.
2027 — First enterprise teams demonstrate full feature regeneration
By 2027, the first enterprise teams will publicly demonstrate the complete Phoenix Architecture workflow — deleting production feature code and regenerating it from specifications and tests, with the regenerated code passing a comprehensive test suite and deploying successfully to production. These demonstrations will do for SDD what Netflix’s chaos engineering demonstrations did for resilience engineering — turning a theoretical practice into a proven industrial technique.
2028 — Proven spec patterns and test libraries become the compounding organisational asset
By 2028 the most productive engineering teams are not those with the best AI tools — everyone has access to the same AI tools. The differentiator is the depth of their accumulated practice library: proven spec patterns refined across dozens of implementations, battle-tested test suites encoding every edge case discovered in production, and mature constitutions capturing hard-won architectural lessons. Teams with three or more years of disciplined SDD can spin up a new product feature in hours by assembling proven spec patterns rather than authoring from scratch. Each pattern carries the accumulated knowledge of every previous implementation — the edge cases, the security constraints, the performance lessons. The first open source spec pattern registries emerge this year, analogous to npm for code — community-contributed, peer-reviewed spec blueprints for common features that any team can adopt and extend. The gap between early SDD adopters and teams starting today is no longer a tooling gap. It is an institutional knowledge gap that takes years to close.
2029 — The team pyramid inversion becomes visible in hiring data
By 2029, the inversion of the team pyramid will be visible in enterprise hiring patterns. Demand for pure implementation roles will have declined measurably. Demand for spec engineers, domain specialists, and AI output evaluators will have grown significantly. Business schools will have introduced courses on specification writing for product managers. Computer science programs will have restructured curricula to emphasize behavioral specification and system design over syntax and implementation.
2030 — AI model upgrades become instant leverage for SDD teams, the moat becomes undeniable
By 2030, the moment that makes the advantage impossible to ignore arrives repeatedly: a new generation AI model releases. For a team with mature specs and comprehensive test suites, the response is immediate — regenerate the entire product against the new model, run the test suite, deploy what passes. Performance improves. Security hardens. Code quality rises. The cost is hours. For a team without specs, the same model upgrade requires evaluating every feature individually, manually testing for regressions, and making judgment calls without a behavioral baseline to validate against. The cost is months. This asymmetry compounds with every model generation. Teams that started building their spec and test library in 2025 or 2026 can now regenerate against Claude 6, GPT-6, or whatever emerges — and immediately benefit. Teams that delayed cannot. The moat is not the specs themselves. It is the regeneration leverage that mature specs and tests give you against each new wave of AI capability — leverage that grows more decisive with every generation.
Conclusion — The Code Burns. The Specs Survive.
Software development is in the middle of a fundamental transition. The scarcity that shaped everything about how teams are organized, how skills are valued, and how code is treated — the scarcity of implementation — is dissolving. AI coding agents have made implementation cheap. What they have not made cheap is clarity. The specification of what software should do, with enough precision that both humans and AI can build from it, remains the hard, valuable, human work at the center of software development.
Spec Driven Development is the methodology built for this transition. It does not fight the fact that AI generates code — it embraces it, and insists on the discipline that makes AI generation reliable. Describe intent. Let AI draft the spec. Review it, own it, refine it. Derive tests from it. Generate code from it. Verify with the tests. Store the spec in git permanently. Let the code burn when something better can be generated.
The connection to Chad Fowler's Phoenix Architecture is not coincidental. Fowler's insight — that the most durable systems will be built from code designed to die — is the architectural principle that SDD, practiced rigorously, makes achievable. The specification is the identity that survives the fire. The test suite is the proof that the phoenix rose correctly. The code is what burns. This is not a future state. It is the logical destination of the discipline we are describing, and teams that build that discipline today will reach that destination first.
The question for every software team is not whether this transition will happen. It is whether they will be building the spec library, the test suite, and the architectural constitution that makes them ready for it — or whether they will still be vibe coding when their competitors start regenerating.
The spec is the asset. The code is the output. The team that owns the best specification library owns the most durable competitive advantage in software.
Describe intent. Let AI draft the spec. Own it. Derive tests from it. Today.
